




I. Présentation▲
Une problématique assez fréquente consiste à mettre à jour le contenu d'une table à partir de données contenues dans une autre table.
Nous allons illustrer cette problématique avec une base assez simple. Cette base contient une table avec des employés (BIGEMP) et une table avec des augmentations (AUGMENTATION)
La table BIGEMP est une duplication de la table exemple Oracle EMP dupliquée 100 000 fois. Il y a 1,4 million d'enregistrements dans cette table. Ci-dessous un extrait de cette table.
La table AUGMENTATION contient le montant des augmentations des employés. Il y a 1,4 million d'enregistrements dans cette table aussi. Ci-dessous un extrait de cette table.
La modification des données que nous souhaitons faire est d'ajouter la valeur de la colonne Montant de la table AUGMENTATION à la colonne SAL de la table BIGEMP.
Dans notre base, tout employé a un enregistrement dans la table des augmentations, cependant nous allons considérer dans cet article que nous n'avons pas la certitude que tous les employés sont présents dans cette table et qu'il ne faut donc augmenter que les employés qui y sont présents et laisser le salaire inchangé pour les autres.
Le résultat désiré est équivalent à la requête suivante :
select E.EMPNO,e.ename,e.sal,a.montant,e.sal+a.montant NouveauSalaire
from bigemp E join augmentation A on e.empno=a.empno
Si vous souhaitez faire quelques tests vous-même, cette base est disponible à l'adresse suivante : http://www.altidev.com/livres.php .
Sous le nom "Base Employés (Grosse)".
Vous pouvez aussi utiliser les scripts présents à la fin de l'article.
II. Utilisation d'un update conventionnel▲
La méthode classique pour réaliser cette modification est d'utiliser un update et une sous-requête corrélée.
update bigemp e
set e.sal = e.sal + (select a.Montant from augmentation a
where a.empno=e.empno)
where e.empno in (select a.empno from augmentation a)ou la variante suivante.
UPDATE bigemp e
SET e.sal = e.sal + (SELECT a.montant FROM augmentation a
WHERE a.empno = e.empno)
WHERE EXISTS (SELECT NULL FROM augmentation a WHERE a.empno = e.empno)Cette solution a un temps d'exécution de 34 secondes et a la trace d'exécution suivante :
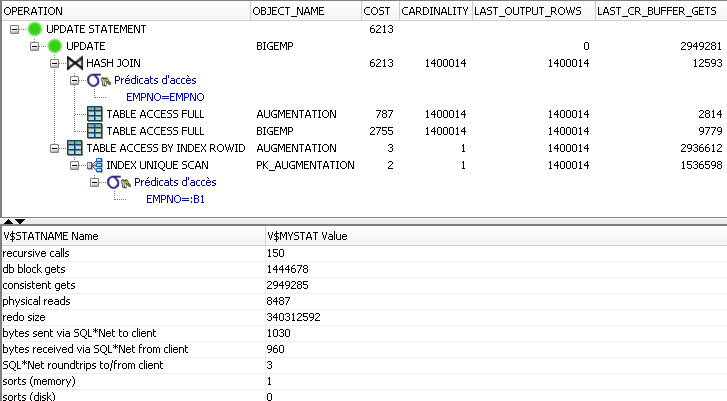
Nous ne commentons pas ces données pour l'instant, le but est de s'en servir comme référence pour les autres solutions.
II-A. Et s'il n'y avait pas d'index ?▲
Nous remarquons que la requête précédente utilise l'index de clé primaire de la table augmentation (PK_AUGMENTATION). Il arrive parfois dans une application que la table qui sert de source aux modifications soit une table temporaire créée sans grande attention et du coup, il est possible qu'elle n'ait pas de clé primaire et encore moins d'index. L'objet de ce paragraphe est d'étudier l'impact de cet oubli.
Nous créons une copie des données sans aucune clé avec la requête suivante :
create table augmentation_sansPK as
select * from augmentationNous collectons les statistiques,
exec dbms_stats.gather_table_stats(user,'augmentation_sansPK');Et exécutons la même requête dessus
update bigemp e
set sal=sal+(select Montant from augmentation_sansPK where empno=e.empno)
where empno in (select empno from augmentation_sansPK )Nous constatons une très nette détérioration puisque le temps d'exécution est à présent de plusieurs heures (je ne sais pas combien car j'ai arrêté avant la fin).
Pourtant le plan d'exécution ci-dessous ne nous laissait pas entrevoir une telle dégradation puisque le coût annoncé était le même.
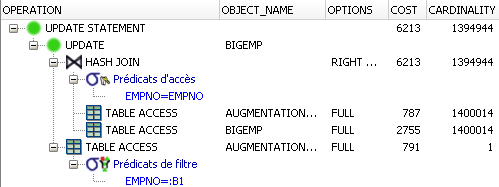
Il faut donc retenir que le champ qui sert à faire le lien dans la sous-requête corrélée doit impérativement être indexé sur ce genre de requête si la table a une taille significative (pour simplifier, considérez que cela est nécessaire à partir de quelques milliers d'enregistrements).
II-B. Et si on utilisait une IOT ?▲
Une table IOT (Index Organized table) est une table qui est organisée en index
(voir https://oracle.developpez.com/guide/architecture/tables/?page=Chap1#L1.4 )
On peut se demander si cette organisation aura un impact sur notre requête.
Nous créons la table avec l'instruction suivante :
create table AUGMENTATION_IOT (
EMPNO NUMBER not null,
MONTANT NUMBER(7,2),
constraint PK_AUGMENTATION_IOT primary key (EMPNO)
) organization indexNous la remplissons
insert into AUGMENTATION_IOT
select * from AUGMENTATIONPuis l'analysons
exec dbms_stats.gather_table_stats(user,'augmentation_IOT');Nous exécutons notre requête
update bigemp e
set sal=sal+(select Montant from augmentation_IOT where empno=e.empno)
where empno in (select empno from augmentation_IOT )Et constatons un temps d'exécution de 25 secondes avec la trace d'exécution suivante :
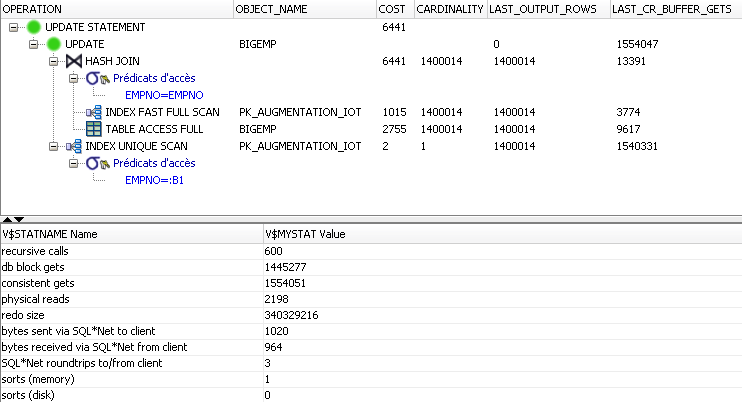
Le résultat est donc que, malgré un coût annoncé plus élevé, le résultat est meilleur avec une table IOT. Cela provient d'une forte baisse des opérations Consistent Gets (-50 %), gagné sur l'opération Table Access By Index RowID sur la table augmentation qui n'est plus nécessaire grâce à la structure IOT (voir colonne LAST_CR_BUFFER_GETS) .
III. Utilisation de l'instruction Merge▲
L'instruction Merge introduite en version 9i d'Oracle est conçue pour fusionner deux tables (voir https://oracle.developpez.com/faq/?page=3-1#merge) cependant elle peut être légèrement détournée de son usage initial pour faire ce genre de requête de mise à jour en ignorant la clause WHEN NOT MATCHED
MERGE into bigemp E using augmentation A on (a.empno=e.empno)
WHEN MATCHED THEN UPDATE set sal=sal+Montant
WHEN NOT MATCHED THEN insert (empno) values (null)Cette notation a l'avantage de ne pas contenir de sous-requête corrélée, ce qui ne déplaira pas aux développeurs peu à l'aise avec ces dernières.
La clause WHEN NOT MATCHED ne nous intéresse pas vraiment, c'est juste qu'elle est obligatoire pour les versions <10g, à partir de la version 10g vous pouvez vous contenter de
MERGE into bigemp E using augmentation A on (a.empno=e.empno)
WHEN MATCHED THEN UPDATE set sal=sal+MontantSi votre table Augmentation contient des employés non présents dans la table Bigemp, le MERGE dans sa version avec clause WHEN NOT MATCHED plantera, car c'est dans le cas présent ce qui me parait le plus adapté.
Côté performances, nous constatons un temps d'exécution de 35 secondes avec la trace d'exécution suivante :
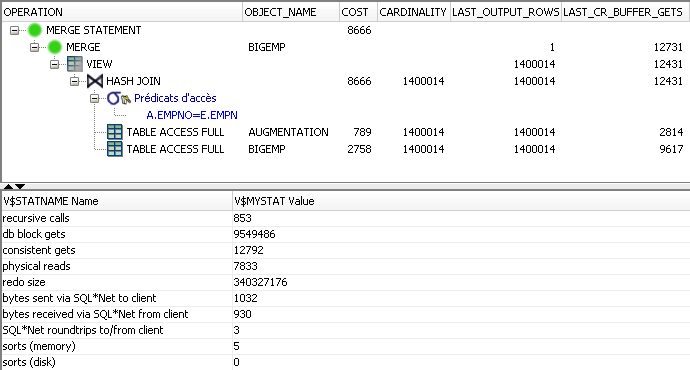
Les performances sont donc moins bonnes que la solution avec un update conventionnel mais il y a des situations où cette solution s'avère 10 à 40 % plus performante.
Par exemple si la table bigemp a une structure IOT l'update conventionnel passe à un temps d'exécution de 44 s alors que la solution MERGE descend à 24 secondes.
Création de la table
create table BIGEMP_IOT
(
EMPNO NUMBER not null,
ENAME VARCHAR2(10) not null,
JOB VARCHAR2(9),
MGR NUMBER,
HIREDATE DATE,
SAL NUMBER(7,2),
COMM NUMBER(7,2),
DEPTNO NUMBER not null,
constraint PK_BIGEMP_IOT primary key (EMPNO)
)
organization index;
insert into BIGEMP_IOT
select * from BIGEMP;
exec dbms_stats.gather_table_stats(user,'bigemp_IOT');Requête merge sur table BIGEMP en IOT
MERGE into bigemp_iot E using augmentation A on (a.empno=e.empno)
WHEN MATCHED THEN UPDATE set sal=sal+Montant;III-A. Et s'il n'y avait pas d'index ?▲
Comme pour la version avec un update conventionnel nous nous posons cette question avec l'instruction MERGE. Nous constatons que le résultat est bien meilleur, puisque ici, il n'y a quasiment pas d'impact, en effet, si on utilise la table augmentation sans index, le temps d'exécution est sensiblement le même que si la table avait une clé primaire (et donc un index). L'utilisation de MERGE semble donc moins sensible à l'absence d'index dans la table source.
III-B. Informations complémentaires sur l'instruction MERGE▲
L'instruction MERGE est apparue avec la norme SQL 2003, elle existe avec une syntaxe équivalente sous MS SQL Server et DB2.
Elle n'est pas disponible sous PostgreSQL, ni sous MySQL.
Dans la clause USING nous avons utilisé une table, mais il est tout à fait possible d'y mettre un select, par exemple
MERGE into bigemp E
using (select * from augmentation where empno<10000) A
on (a.empno=e.empno)
WHEN MATCHED THEN UPDATE set sal=sal+MontantCe qui vous donne toute la puissance du SELECT dans vos requêtes de mise à jour et pas seulement ce qu'on arrive à faire avec une sous-requête synchronisée et cela permet surtout de le faire plus simplement car il est souvent plus aisé d'écrire un SELECT qu'un UPDATE avec des sous-requêtes synchronisées.
Il y a cependant une petite restriction, vous ne pouvez pas mettre à jour une des colonnes stipulées dans la clause ON.
IV. Utilisation d'un Update de sous-requête▲
Une autre façon de faire cette mise à jour est d'utiliser l'instruction UPDATE dans une forme plutôt méconnue qui consiste à faire un UPDATE sur une sous-requête.
update (select sal,Montant from augmentation a
join bigemp e
on a.empno=e.empno)
set sal=sal+MontantCette notation, comme le MERGE, a l'avantage de ne pas contenir de sous-requête corrélée.
Cette solution à un temps d'exécution de 23 secondes et la trace d'exécution suivante
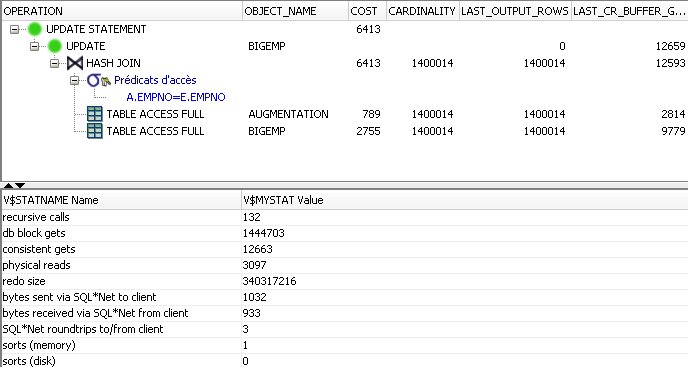
Le temps d'exécution s'est amélioré, et on constate une chute drastique des Consistent Gets. Cette solution est significativement plus performante que l'update conventionnel avec une sous-requête corrélée.
Il y a cependant des restrictions sur les cas où il est possible d'utiliser cette notation. Je n'ai pas trouvé dans la doc la liste de ces cas, mais ils sont plus nombreux que les cas de restriction du MERGE.
IV-A. Et s'il n'y avait pas d'index ?▲
Cette notation n'autorise pas l'utilisation d'une table sans clé primaire dans la sous-requête. Il n'est donc pas possible d'utiliser ce genre de requête avec la table augmentation_sanspk. Si vous êtes dans cette situation, il vous reste soit à indexer votre table soit à utiliser le merge.
V. Conclusion▲
Voilà un résumé des temps d'exécution, même si ce n'est pas forcement le seul indicateur à prendre en compte, ça donne une idée qui convient dans la plupart des situations.
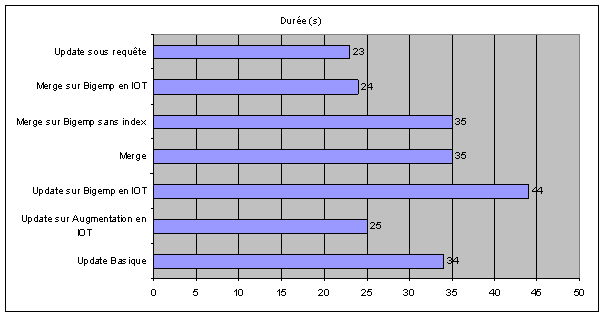
La solution utilisant MERGE a régulièrement de meilleures performances mais rarement de moins bonnes que l'update classique et a l'avantage d'être assez pratique à écrire et de permettre d'écrire simplement des mises à jour compliquées.
La dernière solution, utilisant un UPDATE avec une sous-requête, est légèrement plus performante sur ce cas-là et sur ma machine (sur la machine de Waldar c'est identique au Merge) et est en plus assez élégante à écrire, elle a cependant quelques contraintes d'utilisation qui ne permettent donc pas de l'utiliser dans tous les cas.
Cependant, comme je le dis toujours, en matière de performance, il faut être pragmatique, chaque situation a ses spécificités, il faut donc toujours tester et mesurer dans des conditions équivalentes aux conditions réelles avant de prendre une décision.
Cette phrase peut paraître bateau, mais par exemple sur l'environnement de Waldar le MERGE est systématiquement plus performant que l'update basique alors que sur mon environnement ce n'est pas toujours le cas.
VI. Remerciements et liens▲
Merci à Antoun, Waldar, hmira et Claude pour leur relecture, et Djug de m'avoir guidé.
Article traitant de l'optimisation
https://jpg.developpez.com/oracle/tuning/
Livre optimisation des bases de données (Mise en oeuvre sous Oracle)
VII. Scripts▲
-- Si vous ne l'avez pas déjà
CREATE TABLE EMP (
EMPNO NUMBER(4) PRIMARY KEY,
ENAME VARCHAR2(10) NOT NULL CHECK (ename=UPPER(ename)),
JOB VARCHAR2(9),
MGR NUMBER(4) REFERENCES emp (empno),
HIREDATE DATE,
SAL NUMBER(7,2) CHECK (SAL > 500 ),
COMM NUMBER(7,2),
DEPTNO NUMBER(2) );
Insert into EMP values (7839,'KING','PRESIDENT',NULL,'17/11/81',5000,NULL,10);
Insert into EMP values (7566,'JONES','MANAGER',7839,'02/04/81',2975,NULL,20);
Insert into EMP values (7698,'BLAKE','MANAGER',7839,'01/05/81',2850,NULL,30);
Insert into EMP values (7782,'CLARK','MANAGER',7839,'09/06/81',2450,NULL,10);
Insert into EMP values (7902,'FORD','ANALYST',7566,'03/12/81',3000,NULL,20);
Insert into EMP values (7369,'SMITH','CLERK',7902,'17/12/80',800,NULL,20);
Insert into EMP values (7499,'ALLEN','SALESMAN',7698,'20/02/81',1600,300,30);
Insert into EMP values (7521,'WARD','SALESMAN',7698,'22/02/81',1250,500,30);
Insert into EMP values (7654,'MARTIN','SALESMAN',7698,'28/09/81',1250,1400,30);
Insert into EMP values (7788,'SCOTT','ANALYST',7566,'19/04/87',3000,NULL,20);
Insert into EMP values (7844,'TURNER','SALESMAN',7698,'08/09/81',1500,0,30);
Insert into EMP values (7876,'ADAMS','CLERK',7788,'23/05/87',1100,NULL,20);
Insert into EMP values (7900,'JAMES','CLERK',7698,'03/12/81',950,NULL,30);
Insert into EMP values (7934,'MILLER','CLERK',7782,'23/01/82',1300,NULL,10);
commit;
-- Creation de la table BigEmp
CREATE TABLE bigEMP (
EMPNO NUMBER ,
ENAME VARCHAR2(10) NOT NULL CHECK (ename=UPPER(ename)),
JOB VARCHAR2(9),
MGR NUMBER ,
HIREDATE DATE,
SAL NUMBER(7,2) CHECK (SAL > 500 ),
COMM NUMBER(7,2),
DEPTNO NUMBER NOT NULL )
Tablespace BIG_TABLESPACE ;
-- Insertion des lignes
begin
for i in 0..100000
loop
insert into bigemp
select i*1000+empno, ename, job, i*1000+mgr, hiredate, sal, comm, i*100+deptno
from emp;
end loop;
commit;
end;
/
-- Ajout de la clé primaire et des foreign key
alter table bigEMP add (
constraint PK_BIGEMP primary key(empno) );
begin
dbms_stats.gather_table_stats
(
ownname => user,
tabname => 'BIGEMP',
cascade => true,
estimate_percent => 100,
degree => 2
);
end;
/
CREATE TABLE AUGMENTATION
(
EMPNO NUMBER(12),
MONTANT NUMBER( 4),
CONSTRAINT PK_AUGMENTATION
PRIMARY KEY (EMPNO)
USING INDEX
);
INSERT /*+ append */ INTO AUGMENTATION
SELECT EMPNO, round(dbms_random.value(1, 9999))
FROM BIGEMP;
commit;
begin
dbms_stats.gather_table_stats
(
ownname => user,
tabname => 'AUGMENTATION',
cascade => true,
estimate_percent => 100,
degree => 2
);
end;
/